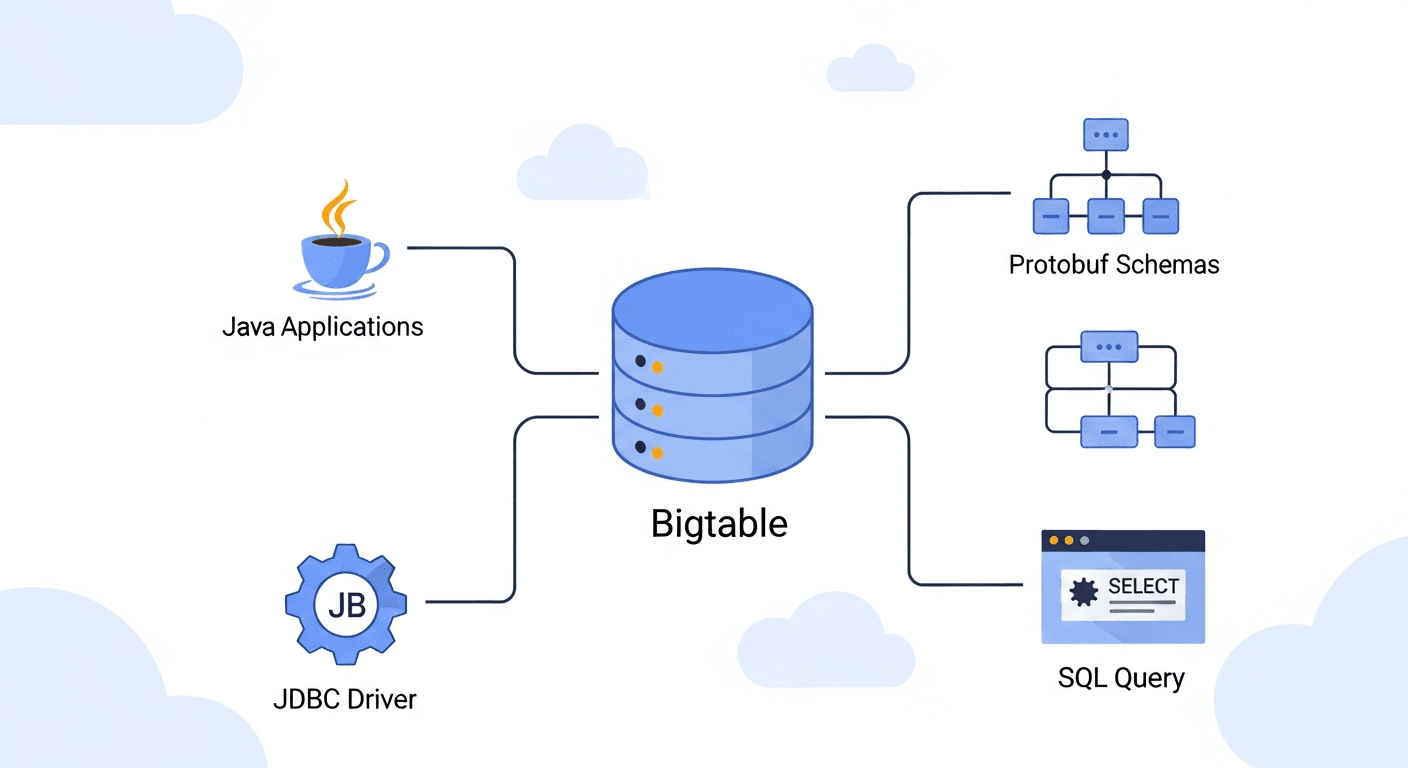
Bigtable: JDBC Driver and Protobuf Schemas Go GA
Connecting Java apps and querying nested Protobufs in Bigtable just got way easier.
Alright, Bigtable users, you're gonna like this. Two really handy features for Bigtable just hit General Availability. This is pretty cool because it means they're officially ready for prime time, and honestly, they're going to make a lot of lives easier.
First up, Bigtable now has a JDBC driver. For anyone who's ever tried to connect Java applications or other reporting tools to Bigtable, you know this is a big deal. Before, it could be a bit of a dance, involving custom connectors or specific client libraries. Now, with a standard JDBC adapter, connecting your existing Java apps is way, way simpler. You can just plug right in! This means you can pull data directly into all those Java-based reporting tools and applications you already use, streamlining your workflows if you're deeply embedded in the Java ecosystem. It removes a pretty annoying integration hurdle for a lot of folks.
But wait, there's more! The second big announcement is about protobuf schemas. Honestly, this one is a real game-changer for how you interact with your data in Bigtable. If you're storing protobuf messages as bytes in Bigtable (and many high-throughput applications are), you can now query individual fields within those protobuf messages.
Think about that for a second. Instead of pulling out the entire protobuf blob and then deserializing it in your application just to grab one specific piece of info, you can now use GoogleSQL for Bigtable to dig right into those nested fields. That's a huge win for efficiency, reducing the processing load on your applications and simplifying your queries. And it's not just GoogleSQL; this new capability also works seamlessly with continuous materialized views, logical views, or even BigQuery external tables. This opens up a lot more flexibility in how you analyze and work with your protobuf data, without a lot of extra, manual transformation steps. It makes Bigtable feel a lot more like a traditional relational database in how you can interact with complex data structures, but still with all the amazing scale and low-latency performance it offers for massive datasets.
These two features really make Bigtable more accessible and powerful for a broader range of applications and data engineering patterns. No more jumping through hoops to get your Java apps connected, and way easier, more efficient data analysis for your protobufs. It's a solid upgrade to a core GCP service. Go check it out and see how it can simplify your Bigtable interactions!