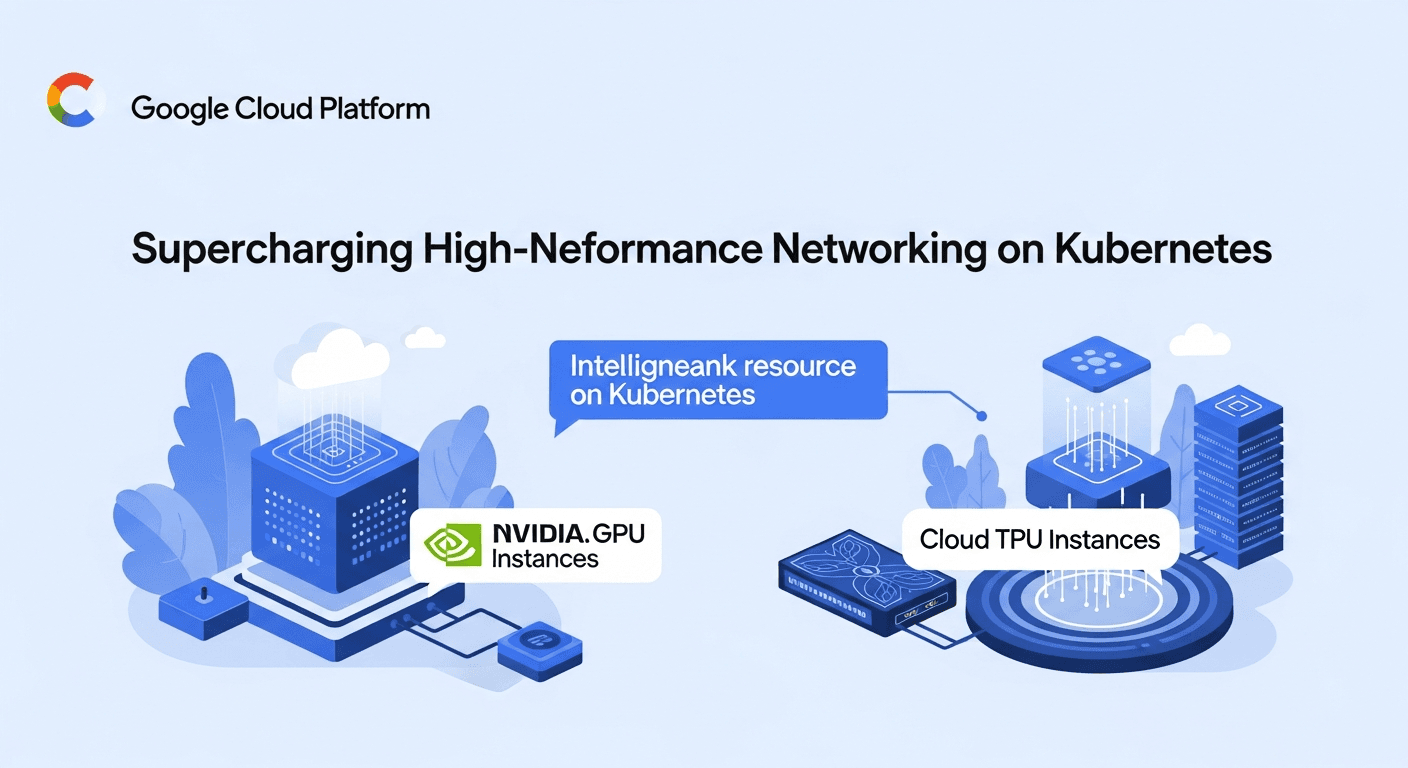
GKE Managed DRANET is GA: Supercharging High-Performance Networking on Kubernetes
Get ready for blazing fast networking for your AI/ML workloads on GKE, thanks to Dynamic Resource Allocation.
If you've ever tried to run some serious AI or machine learning workloads on Kubernetes, you know networking can be a real pain point. Moving massive datasets around, especially when you're dealing with GPUs and TPUs, often feels like trying to pour a gallon of water through a tiny straw. It's just not efficient, and honestly, it can slow down your entire development cycle.
Well, Google Cloud just made things a whole lot better. They've announced that GKE managed DRANET is now Generally Available (GA). And this is pretty cool news for anyone pushing the limits of high-performance computing on GKE.
So, what exactly is DRANET? It stands for Dynamic Resource Allocation for NETworking. Basically, it's a managed feature that uses the Kubernetes Dynamic Resource Allocation (DRA) API. Think of it like this: instead of manually fiddling with network configurations and trying to optimize every little bit, DRANET handles it for you. It intelligently allocates network resources, making sure your high-performance applications get the bandwidth they need, right when they need it.
This is a game-changer, really. Especially with the GA release expanding support to include NVIDIA GPU Instances (like the A3 Ultra, A4, A4X, and A4X Max) and Cloud TPU Instances (v6e and v7x). We're talking about the hardware that powers the most demanding AI and ML tasks. And now, GKE can manage the networking for these resources in a much more efficient way.
Before, getting these high-performance setups to play nicely with networking could be a headache. You'd spend time on optimization that wasn't directly related to your actual work. But with DRANET, GKE does the heavy lifting. This means you can focus on training your models, running complex simulations, or whatever high-compute task you're tackling, without worrying as much about the underlying network plumbing.
The core idea is to simplify resource allocation for those critical network components. This isn't just about speed, it’s about making your life easier and letting you get more out of your expensive hardware. And that's something we can all appreciate.
If you're running AI/ML workloads on GKE with GPUs or TPUs, you should definitely check this out. It can significantly improve your network performance and streamline your operations. You can learn more about how to allocate network resources using GKE managed DRANET in the official documentation.
Here's the link if you want to dive deeper: Allocate network resources by using GKE managed DRANET And the original release note: April 08, 2026